How to get a job as a Data Engineer (Part 1)

How to Get a Job as a Data Engineer (Part 1)
In this series of articles, I want to help you secure a job as a data engineer. This first article will assess your current situation and outline what you need based on where you are in your career.
Understanding Your Starting Point
The purpose of this post is not to teach you specific technologies yet; it’s to help you understand your starting point and the steps you need to take to become a data engineer.
Starting any new venture can be tough, and data engineering is no exception. Is it worth it? Getting a job as a data engineer has been the best career decision of my life. Yes, it’s worth it.
The fantastic news is that you can become a data engineer too. Our circumstances vary, and your path could be longer or shorter than mine. With the right attitude and commitment, anyone can get there.
Note the diagram below. From your starting point, you have a set of core skills. If you have work experience, you might also have contextual knowledge. Both the core skills and your contextual knowledge play a key role in becoming a complete data engineer. Take some time to write down the skills and expertise listed to understand the areas to pay more attention to.
Assess Your Current Career Stage
From the diagram, prospective data engineers can come from various backgrounds, such as:
- Data Scientists
- Software/Backend Developers
- Data Analyst
- Students
Each starting point follows a different path, and our destinations vary. For instance, if you’re a data scientist who loves stats and math, you might become a data engineer specializing in those fields or an ML Engineer. The same applies to backend developers with a SQL background and others from different fields.
Here is an illustration of the overlap between a data scientist’s skills and the knowledge of a data engineer. Both have Soft Skills as a Core Skill, but your situation might vary.
Understanding Core Skills
Let’s look at some of the core skills listed in the diagram in more detail.
Programming
Programming is a core skill for data engineers. Python, SQL, and Scala are popular languages because they are powerful tools for solving data problems. We don’t use these languages out of preference or love for coding; we use them to add value by solving problems.
Should you learn Python?
Yes if:
- You have a problem you want to solve using it.
- You’re an analyst without programming experience.
- You’re a developer coming from another language, like .Net.
No if:
- You’re unsure where to start and want to read a Python book end-to-end.
- You already have a background in Python.
- You don’t have a problem to solve with it yet.
Learn Python (or any language) as a means to an end, not as an end itself.

Databases and Data Warehousing
As a data engineer, you should understand data technologies, including databases and data warehousing. SQL is the lingua franca of relational databases and a great starting point.
For example, imagine you just got hired as a data engineer at a start-up with tight budgets. Your boss wants you to analyze a CSV file with over 20 million rows, which is too large for spreadsheet programs. If you’re proficient in Python, you could use Pandas or Polars. If not, DuckDB is a viable alternative.
Consider the following questions:
- What database system should I choose?
- What are the questions about the data I need to answer?
- Are there technologies/tools I am confident with that I can leverage?
- How do I scale my solution?
- How much will it cost?
Understanding the importance of asking the right questions is more important than coming up with smart answers. In most data projects I’ve worked on, the questions remain constant, but the technical challenges and agendas vary.
Cloud Computing
Businesses move to the cloud primarily to save and make money. If you aim to work for such a company, it’s crucial to understand cloud computing. Even non-profits strive to avoid unnecessary expenses, and cloud computing addresses one of the most significant challenges faced by modern enterprises: scalability.
Imagine having the ability to help a company scale efficiently, save costs, and operate swiftly. The value of such skills is immense. Therefore, learning about cloud computing is essential for modern data engineering.
Major Cloud Providers: AWS, Azure, and GCP
The three major cloud providers—AWS, Azure, and GCP—offer a range of similar products. To get an in-depth comparison, you can refer to this link. As a student, your focus should be on understanding the common problems each product aims to solve.
Example: Cloud Storage Solutions
Consider the fundamental example of storage. When you need to store a large amount of data (in the form of objects, like files) for an indefinite period, cloud storage is the ideal solution. Each major cloud provider offers a storage service:
- AWS: Amazon S3
- GCP: Google Cloud Storage
- Azure: Azure Blob Storage
While Amazon S3 and Google Cloud Storage are almost identical, Azure Blob Storage has slight differences in implementation. However, the key point is that all these services solve the same problem: providing nearly infinite, cost-effective storage that is reliable and durable.
Knowledge of the cloud can be viewed as contextual. As a student, you want to start with what you know already and expand upon it. I knew SQL and learning about cloud databases was a natural progression. Think about what you have the most confidence in and work out a path to covering what’s required of a data engineer.
Data Workflow Management
Data workflow management tools like Airflow are crucial for scheduling and running processes in a specific order. As a data engineer, you’ll ensure that data gets extracted, transformed, and loaded (ETL) using these orchestration tools.
Imagine you need to move data in AWS as shown in the following flowchart
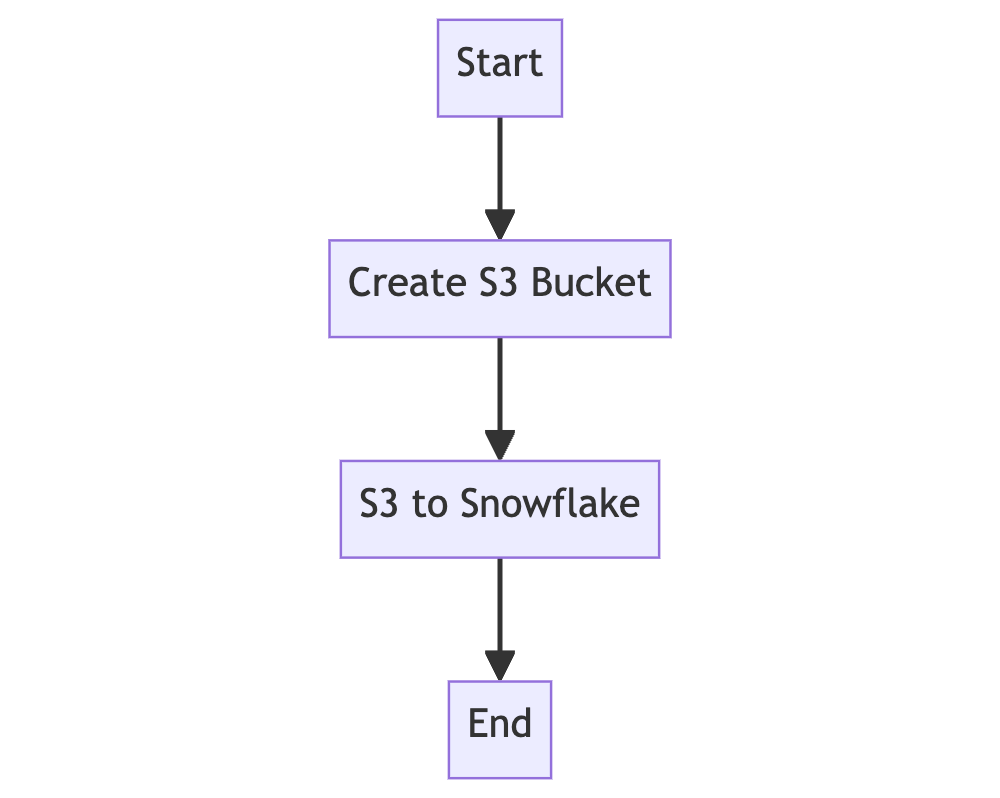
The simple flow shows that you want to create an S3 bucket and copy data from the bucket to a Snowflake table. The code might look like this:
from airflow import DAG
from airflow.providers.amazon.aws.transfers.s3_to_snowflake import S3ToSnowflakeOperator
from airflow.providers.amazon.aws.operators.s3 import S3CreateBucketOperator
from airflow.providers.snowflake.operators.snowflake import SnowflakeOperator
from airflow.operators.dummy import DummyOperator
from datetime import datetime
# Define default arguments
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 1, 1),
'retries': 1,
}
# Define the DAG
with DAG(
's3_to_snowflake_dag',
default_args=default_args,
description='Ingest data from S3 to Snowflake',
schedule_interval='@daily',
catchup=False,
) as dag:
# Define the tasks
start = DummyOperator(
task_id='start',
)
create_s3_bucket = S3CreateBucketOperator(
task_id='create_s3_bucket',
bucket_name='my-s3-bucket',
aws_conn_id='aws_default',
)
s3_to_snowflake = S3ToSnowflakeOperator(
task_id='s3_to_snowflake',
stage='MY_STAGE',
table='MY_TABLE',
schema='PUBLIC',
file_format='(type = \'CSV\', field_optionally_enclosed_by=\'"\')',
s3_keys=['s3://my-s3-bucket/my-data.csv'],
snowflake_conn_id='snowflake_default',
)
end = DummyOperator(
task_id='end',
)
# Define the task dependencies
start >> create_s3_bucket >> s3_to_snowflake >> end
Even if you’ve never coded in Python, you can read through the code and understand how it maps to the flowchart that precedes it.
Software Engineering Principles
Data engineering borrows heavily from software engineering principles. Practices like CI/CD pipelines, observability, and established patterns are essential for maintaining structured and efficient data platforms.
Before data became data engineering, testing was never considered part of what we do. We still make jokes about testing our code in production. Today, we take testing seriously. Here’s an example:
# test_etl.py
import pytest
from etl_extract import extract_data_from_s3
from etl_transform import transform_data
from etl_load import load_data_to_snowflake
def test_extract_data_from_s3():
# Mock S3 extraction logic
data = extract_data_from_s3('test-bucket', 'test-data.csv')
assert data is not None
def test_transform_data():
raw_data = ... # Some raw data
transformed_data = transform_data(raw_data)
assert transformed_data == ... # Expected transformed data
def test_load_data_to_snowflake():
transformed_data = ... # Some transformed data
load_data_to_snowflake(transformed_data)
# Add assertions to verify data loading if possible
if __name__ == "__main__":
pytest.main()
test_extract_data_from_s3 tests that the extraction logic works. I.e. the logic in extract_data_from_s3. test_transform_data the transformation logic and test_load_data_to_snowflake the loading logic. This example is naive but the concept of testing is a powerful shift for data people. Other software principles, such as documentation, modularity and config management, helped mature the data engineering field.

Soft Skills
Soft skills are often the most overlooked aspect of data engineering. I’ve found that listening attentively to users and communicating effectively can be invaluable in situations where many others give up.
Communication doesn’t come naturally to me—I am a nerd and an introvert. I must force myself to pay attention, but it’s often worth the effort.
Empathy is another skill that tech professionals might struggle with, but it can and should be learned. Understanding what a frustrated user feels when waiting for a simple report to execute provides insight into the data problems within a company. This understanding leads to solutions, and high-value Data Engineers practice empathy.
Critical thinking involves analyzing facts to form a judgment, making unbiased decisions, and thinking clearly and rationally. It’s essential for making good decisions. Can AI think critically? While AI can analyze vast amounts of data, creativity and abstract reasoning remain uniquely human traits.
Soft skills are difficult, if not impossible, to replace with AI.
Summary
In this first article, we’ve explored some essential skills for successful data engineers. There is still a lot to cover, but the journey is exciting and well worth the effort.
Thanks for reading, and keep learning!
Do you have any questions or thoughts on starting your journey to becoming a data engineer? Leave a comment below or reach out to me on social media!